关于 Go 的内存结构在 Go 内存模型 中已经有介绍,但是内容相对简单,许多细节也一带而过。Ross Cox 的这篇文章 Go Data Structure 讲解得比较系统也很全面的一篇。翻译至此,希望能对大家有帮助。
2009 年的旧文,发现自己当时没有翻译完。所以再次做了增补和修改。如果我没记错,应该已经有人在 OSC 上发表过同一篇文章的翻译了。大家对照参考阅读吧。
————翻译分隔线————
Go 数据结构
每当给新手介绍 Go 的时候,我发现为了建立起关于哪个操作成本更加高昂的正确观念,将 Go 如何为其值分配内存说明清楚会很有帮助。本文介绍了基础类型、结构体、数组和切片(slice)。
基本类型
先来看看几个简单的例子:
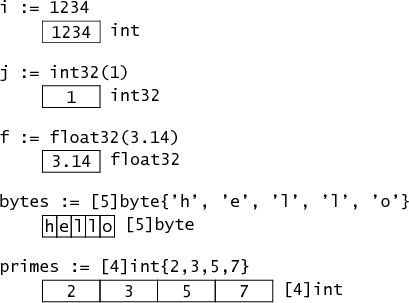
变量 i 的类型是 int,在内存中表现为一个 32 位的字。(所有图展示的都为 32 位内存结构;在当前的实现里,在 64 位的架构中只有指针会变大,int 仍然还是 32 位,不过也可能选择 64 位来作为替代实现。)
由于显式的转换,变量 j 的类型是 int32。虽然 i 和 j 有相同的内存布局,但是它们是不同的类型:赋值 i = j 会产生一个类型错误,因此必须显式的进行转换:i = int(j)。
变量 f 的类型是 float,当前的实现是 32 位的浮点类型。它的内存占用与 int32 一样,但内部布局不同。
结构体与指针
接下来,变量 bytes 的类型是 [5]byte,一个有 5 字节的数组。它的内存表现就是这 5 个字节,跟 C 的数组一样一个个挨着。类似的 primes 是一个有 4 个 int 的数组。
Go,更接近 C 而不是 Java,它为程序员提供了是不是指针的权力。例如,这个类型定义:
type Point struct { X, Y int }
定义了一个叫做 Point 的简单的结构类型,在内存中表现为两个相邻的 int。
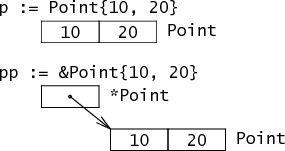
复合文法语句 Point{10, 20} 对 Point 进行了初始化。对一个复合文法进行取地址表示了一个指向刚刚分配并初始化的 Point 的指针。前者在内存中是两个字;后者是一个指向两个字的内存的指针。
结构体中的字段在内存中是一个挨一个的排布的。
type Rect1 struct { Min, Max Point }
type Rect2 struct { Min, Max *Point }
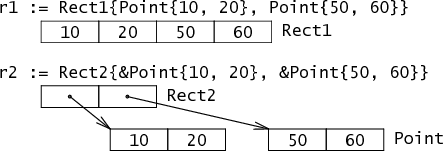
Rect1,一个有两个 Point 字段的结构体,表达成一行有两个 Point,或者说四个 int。Rect2,一个有两个 *Point 字段的结构体,表达成两个 *Point。
那些使用过 C 的程序员可能不会对 Point 字段和 *Point 字段之间的区别感到惊讶,而哪些仅仅使用过 Java 或 Python(以及其他……)可能对决定使用哪种而感到诧异。通过为程序员提供了基本的内存布局控制能力,Go 提供了对一组数据结构的整体大小、分配数量和内存访问模式进行控制的能力。所有都是构建能够良好运行的系统的关键。
字符串
有了前面这些铺垫,我们可以继续了解那些更加有趣的数据类型了。
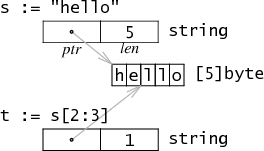
(灰色箭头表示存在于实现中,但是无法在程序中直接看到的指针。)
一个 string 在内存中表现为双字结构体,包含指向字符串数据的指针和其长度。由于 string 是不可变的,因此多个字符串共享同一存储空间是安全的。那么如果对 s 进行切,片使其成为一个新的双字结构体,会在内部生成另一个指针和长度,但仍然指向相同的字节序列。这意味着切片可以在不进行任何分配和复制的情况下完成,因此切片同指定序号轮寻字符串同样有效率。
(从另一方面来说,在 Java 和其他语言中将字符串切片到更小的片段时,有一个众所周知的问题,即便是只有一个小片段被使用的情况下,原始的引用都将在内存中保留整个原始字符串。Go 也有同样的问题。我们已经尝试但拒绝了一个使用分配和复制的替代方案,这个方案会让字符串切片的成本更加高昂,大多数程序都希望避免这一情况。)
slice
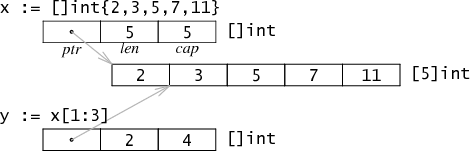
一个 slice 是指向一个数组的某个片段的引用。在内存中,它是一个三字结构体,包含了指向首元素的指针、slice 的长度和容量。长度是类似 x[i] 这样的索引操作的上限,而容量是 x[i:j] 这样的切片操作的上限。
与对字符串切片一样,对数组切片也不会产生复制:它仅仅创建一个新的用于保存不同的指针、长度和容量的结构体。在这个例子中,复合文法 []int{2, 3, 5, 7, 11} 创建了一个包含有五个值的新数组,然后设置了 slice x 的字段来描述这个数组。slice 表达式 x[1:3] 没有分配任何数据:它只是填充了一个指向相同底层存储的新的 slice 结构体。在例子中,长度为 2,y[0] 和 y[1] 是唯一合法的序号;而容量是 4,y[0:4] 是一个合法的 slice 表达式。(参阅 Effective Go 了解更多关于 slice 长度和容量,以及如何使用的内容。)
由于 slice 是一个多字结构体,在没有指针的情况下,切片操作不需要分配内存,甚至是 slice 头也不需要,它通常保存在栈上。这使得 slice 的使用与在 C 中传递指定的指针和长度的成本一样低廉。Go 最初将 slice 作为一个指向上面展示的结构体的指针,但是这样的话意味着每一个切片操作都会分配新的内存对象。即便使用快速分配也为垃圾回收器产生了许多额外的工作。我们发现了这一情况,就像前面在字符串部分已经提及的,这种情况下程序可能会避免切片操作而使用轮寻。移除了这些间接量与内存分配,使得 slice 的成本已经足够低廉,在大多数情况下都不需要轮寻了。
new 和 make
Go 有两个数据结构创建函数:new 和 make。它们的区别最初可能引起混淆,不过很快就会感到正常。最基本的区别是 new(T) 返回一个 *T,一个 Go 程序可以隐式抛弃的指针(图中黑色箭头),但 make(T, args) 返回一个原始的 T 而不是指针。通常 T 有其内部隐式实现的指针(图中灰色的箭头)。new 返回一个指向空值填充的内存,而 make 返回一个复杂的结构体。
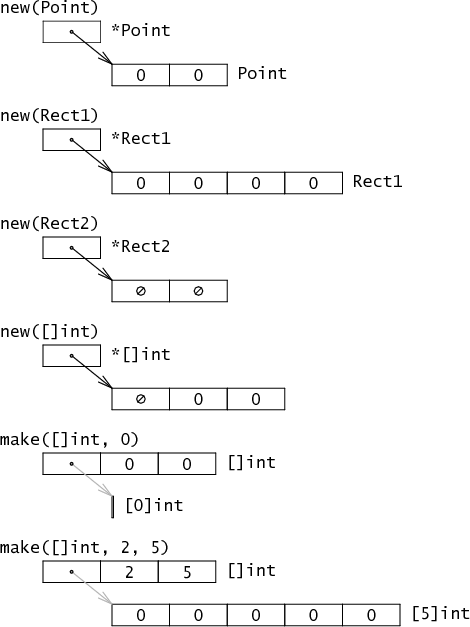
有一种办法可以将这两种情况统一起来,不过可能会颠覆从 C 和 C++ 而来的传统:定义 make(*T) 来返回一个指向新分配的 T 的内存,那么当前 new(Point) 可以写为 make(*Point)。我们对此尝试了几天,但是觉得这与人们通常希望的内存分配函数实在大相径庭。
即将来临
这已经够长了。接口值、map 和 channel 将只能等待以后的文章了。
Leave a Reply